빅데이터/통계 이론
2. 연속 확률 분포
갓우태
2019. 6. 19. 02:30
지난 포스트에서 알아본 연속 확률 분포 종류
정규분포, 표준 정규분포, t분포, 카이제곱, F, 와이블,, 을 파헤쳐 보겠습니다.
정규분포
- 정의
연속형 확률변수 X가 우연적 상태에서 무한히 집합할 때, 중심값 근처에 대다수가 밀집되는 좌우 대칭의 종 모양 분포가 형성된다.
는데,, 쉽게 말해 확률값이 좌우대칭인 종이다!(변수가 연속, 실수일 때)
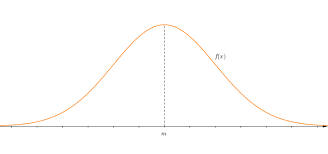
- 용도
수집된 자료의 분포를 근사하는 데에 자주 사용한다. (중심 극한 정리에 의하면, 독립적인 확률변수들의 평균은 정규분포에 가까워지는 성질이 있다고 함!
표준 정규분포
- 정의
정규분포 밀도 함수를 통해 X를 Z로 정규화함으로써 평균이 0, 표준편차가 1인 표준 정규분포
쨋든, 정규분포인데 평균이 0, 표준편차가 1인거닷
실습
우선 몇 가지 파이썬 패키지가 필요하다.
- numpy : 행렬 연산 패키지
- scipy : 과학 계산 패키지
- scipy.stats : 통계 분석 패키지
- pandas : 데이터 패키지(데이터베이스랑 비스무리)
- matplotlib : 데이터 시각화 패키지 (위의 정규분포표 그림처럼 시각화할 수 있음)
- seaborn : 마찬가지로 데이터 시각화 패키지
- statsmodels : 통계 분석 패키지
anaconda를 사용하면, 모두 conda install로 설치 가능하다~~ 꿀
- 모듈 불러오기
|
1
2
3
4
5
6
7
|
import numpy as np
import scipy.stats
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
import seaborn as sns
|
- 정규분포 데이터 생성
|
1
2
3
4
|
# seed 선택을 하여, 매번 실행 시 동일한 값이 나오도록 설정
# 평균 20, 표준편차 2, 데이터 수 100000의 정규분포 따르는 데이터 생성
|
- 히스토그램으로 데이터 분포 확인!
|
1
|
|

와우 신기방기~~
전체 코드는 https://github.com/godute/BigData/blob/master/statistics/stats_test.ipynb
godute/BigData
BigData 연습 jupyter notebook. Contribute to godute/BigData development by creating an account on GitHub.
github.com
에서 확인할 수 있습니다.
반응형